Varför detta är viktigt
GPU-minne, inte FLOP, är det hårda taket för hur stor LLM man kan ladda och hur länge en kontext kan betjänas. BF16-modeller använder 16 bitar per vikt; det fördubblar fotavtrycket i förhållande till INT8-kvantor men bevarar träningstidens exakthet.DFloat 11 (DF11) komprimerar BF16 förlustfritt till ≈11 bitar genom Huffman-kodning av det glesa exponentfältet.
Resultat: ~30 % mindre fotavtryck vid körning, 100 % identiska utdata.
Rubrikvinster på riktigt silikon
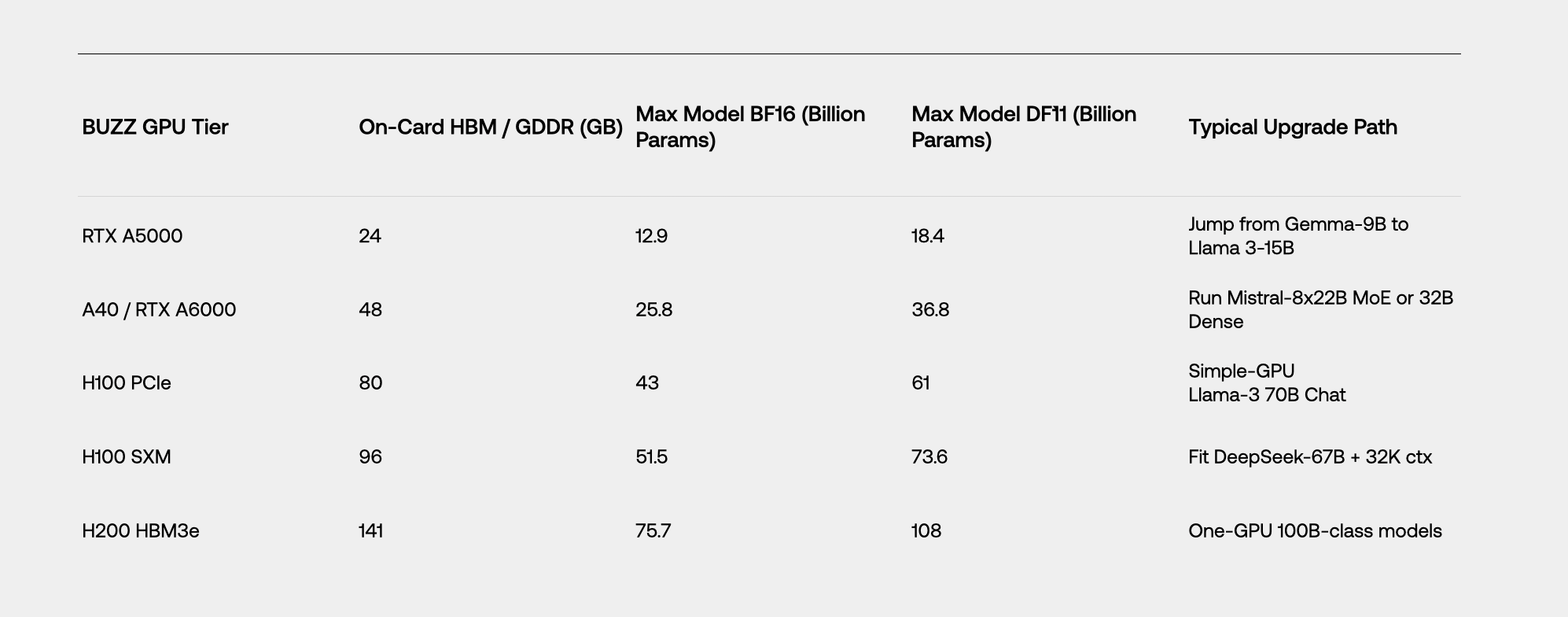
KV-cache vinner. Eftersom DF11 också komprimerar aktiveringar krymper varje tokens KV-poster med 30 %. På långa kontextarbetsbelastningar (chatthistorik, RAG, ERP-dokument) som översätts till +43 % kontextlängd innan tokens blir ogiltiga.
Prestanda i praktiken
- Genomströmning: Vid batch ≥ 32 amorteras DF11-avkodning; på en A100 40 GB mätte teamet endast 2 % långsammare än BF16.
- Latensgränsfall: Batch = 1 ser ~40 % träff – använd BF16 när du redan passar och bara bryr dig om enkel prompt-ping.
- Slår CPU-avlastning med ×38 när alternativet är att spilla till RAM.
Så här använder du DF11 på BUZZ
- Hugging Face: färdiga DF11-kontrollpunkter för Llama 3.x, Qwen 2.x, Mistral osv.
- DIY:
dfloat11.compress.py your_model_dirproducerar en DF11 →.ptkompatibel med vLLM och TensorRT‑LLM. - Blandade flottor: Buzz schemaläggare låter dig packa DF11-shards över heterogena GPU:er; DF11 förblir lite exakt så att resultat över flera enheter förblir deterministiska.
Kostnadspåverkan
Kör Llama‑3‑70B‑Instruct på en enda H100‑80 GB med DF11 jämfört med dubbla H100 med BF16:

Årligen är det en besparing på över 47 000 dollar per replika före strömrabatter.
När du inte ska använda DF11
- Du är nöjd med förlustfri W8A8-kvantisering och har redan validerat kvalitet.
- Latenskritiska batch 1-slutpunkter som redan passar i VRAM.
- Träning eller full gradientfinjustering (exponentbitar ändras).
Effektivitet väcker aptit med Jevons paradox
År 1865 observerade ekonomen William Stanley Jevons att teknisk effektivitet tenderar att öka den totala förbrukningen av en resurs – eftersom lägre kostnader låser upp nya användningsfall. BUZZ ser redan denna dynamik med DF11-piloter:
- Team som bara hade råd med 7‑B‑parameterassistenter förra kvartalet kör nu 34‑B chatbots – och behöver fyra gånger så lång kontext.
- RAG-integratörer som pressade in inferens i en GPU per användare lanserar nu burst-pooler med 20 – 30 instanser för att hantera fullständig omrankning av dokument.
Att ta med sig: DF11 minskar enhetskostnaden, men den sammanlagda efterfrågan kommer sannolikt att överträffa besparingarna. BUZZ kommande datacenterutbyggnad – plus nytt H100/H200-lager – säkerställer att kapaciteten håller jämna steg med Jevons-kurvans uppgång.
Design för skala: behandla din DF11-migrering som steg 1. Steg 2 är automatisk skalningspolicy, placeringsgrupper och inter-GPU-hastighet (NVLink vs PCIe) så att du kan rida på efterfrågevågen utan flaskhalsar.



