Por qué es importante
La memoria de la GPU, y no los FLOP, es el límite máximo de tamaño de un LLM que se puede cargar y la duración del contexto que se puede ofrecer. Los modelos BF16 utilizan 16 bits por peso, lo que duplica el espacio ocupado en comparación con la cuantificación INT8, pero conserva la fidelidad del tiempo de entrenamiento. DFloat 11 (DF11) comprime el BF16 sin pérdidas a ≈11 bits mediante la codificación de Huffman del campo del exponente disperso.
Resultado: huellas un 30 % más pequeñas aproximadamente en el tiempo de ejecución y resultados 100 % idénticos.
Grandes ganancias en silicio real
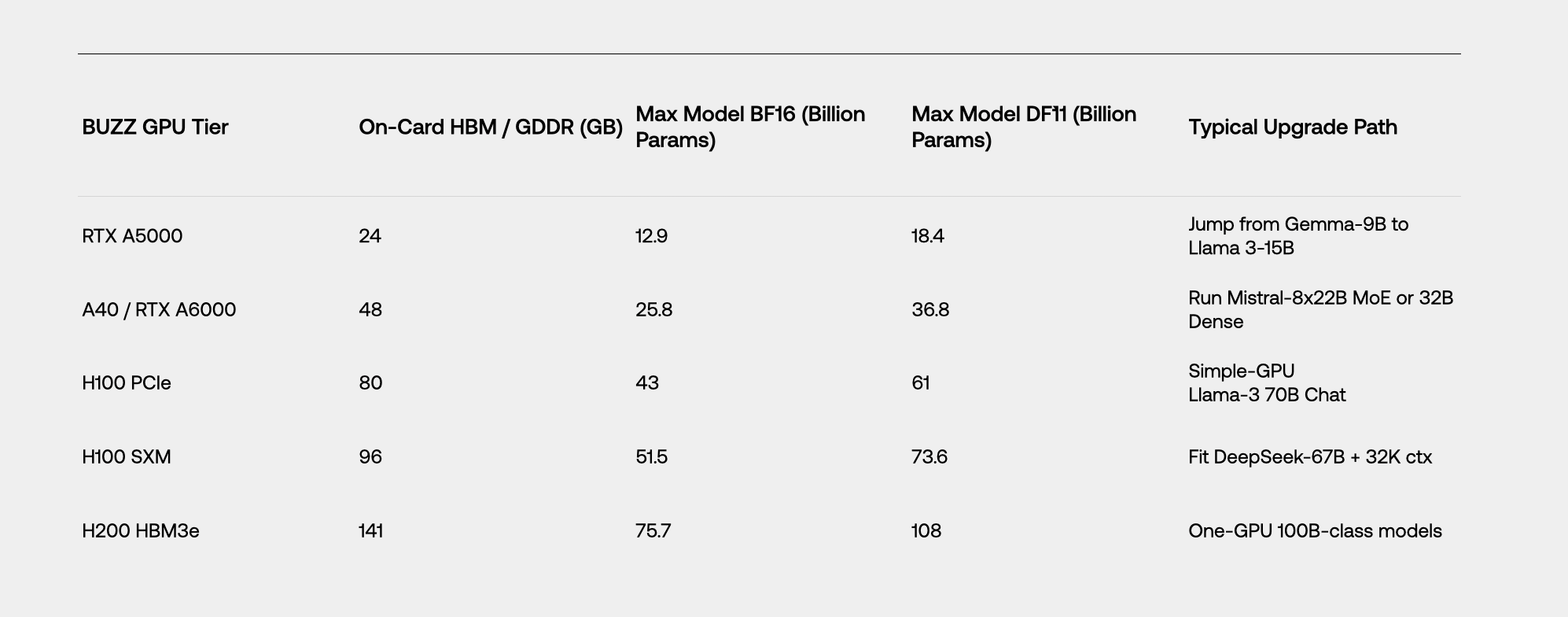
La caché KV gana. Debido a que el DF11 también comprime las activaciones, las entradas KV de cada token se reducen en un 30 %. En cargas de trabajo de contexto largo (historial de chat, RAG y documentos ERP), eso se traduce en un 43 % más de longitud de contexto antes de expulsar los tókenes.
El rendimiento en la práctica
- Rendimiento: en el lote ≥ 32, la decodificación del DF11 se amortiza; en un A100 de 40 GB, el equipo observó que solo era un 2 % más lento que el BF16.
- Casos extremos de latencia: el lote = 1 contempla un 40 % de aciertos aproximadamente. Utiliza el BF16 cuando ya encaje y solo le importe el ping de una sola solicitud.
- Supera la descarga de la CPU en ×38 cuando la alternativa es el desbordamiento a la RAM.
Cómo usar el DF11 en BUZZ
- Hugging Face: puntos de control de DF11 listos para usar para Llama-3.x, Qwen 2.x, Mistral, etc.
- DIY:
dfloat11.compress.py your_model_dirproduce un DF11 →.ptcompatible con vLLM y TensorRT‑LLM. - Flotas mixtas: el programador de Buzz te permite empaquetar fragmentos de DF11 en GPU heterogéneas; el DF11 se mantiene exacto en bits, por lo que los resultados entre los dispositivos siguen siendo deterministas.
Impacto en los costes
Ejecutar Llama‑3‑70B‑Instruct en un solo H100 de 80 GB con el DF11 frente a dos H100 con BF16:

Anualizado, eso supone un ahorro de más de 47 000 dólares por réplica antes de los reembolsos de energía.
Cuándo no usar el DF11
- Si te satisface la cuantificación W8A8 con pérdidas y ya has validado la calidad.
- Puntos finales del lote 1 críticos para la latencia que ya encajan en la VRAM.
- Entrenamiento o ajuste de gradiente completo (los bits del exponente cambian).
La eficiencia genera apetito con la paradoja de Jevons
En 1865, el economista William Stanley Jevons observó que las eficiencias técnicas tienden a aumentar el consumo general de un recurso, porque un coste más bajo posibilita nuevos casos de uso. BUZZ ya ve esta dinámica con los pilotos DF11:
- Los equipos que solo podían permitirse asistentes de parámetros de 7 B el trimestre pasado ahora están creando chatbots de 34 B y necesitan cuatro veces la longitud del contexto.
- Los integradores de RAG que exprimieron la inferencia en una GPU por inquilino ahora lanzan grupos de ráfagas de 20-30 instancias para gestionar la reclasificación completa de documentos.
Conclusión: el DF11 reduce el coste unitario, pero la demanda agregada probablemente superará el ahorro. La próxima expansión del centro de datos de BUZZ, además del nuevo inventario H100/H200, garantiza que la capacidad siga el ritmo del repunte de la curva de Jevons.
Diseño para escalar: trata tu migración a DF11 como el paso 1. El paso 2 es la política de escalado automático, los grupos de ubicación y la velocidad de la GPU (NVLink frente a PCIe) para que puedas aprovechar la oleada de demanda sin cuellos de botella.



