Pourquoi est-ce important ?
La mémoire GPU, plutôt que les FLOPs, fixe le plafond strict de la taille des LLM chargeables et de la longueur de contexte pouvant être prise en charge. Les modèles BF16 utilisent 16 bits par poids, ce qui double l’empreinte par rapport aux quants INT8, tout en conservant la fidélité du modèle à l’entraînement. DFloat 11 (DF11) permet une compression sans perte du BF16 à environ 11 bits grâce à un codage de Huffman du champ d’exposant peu dense.
Résultat : ~30 % d’empreintes plus petites au moment de l’exécution, 100 % de sorties identiques.
Gains importants sur le silicium réel
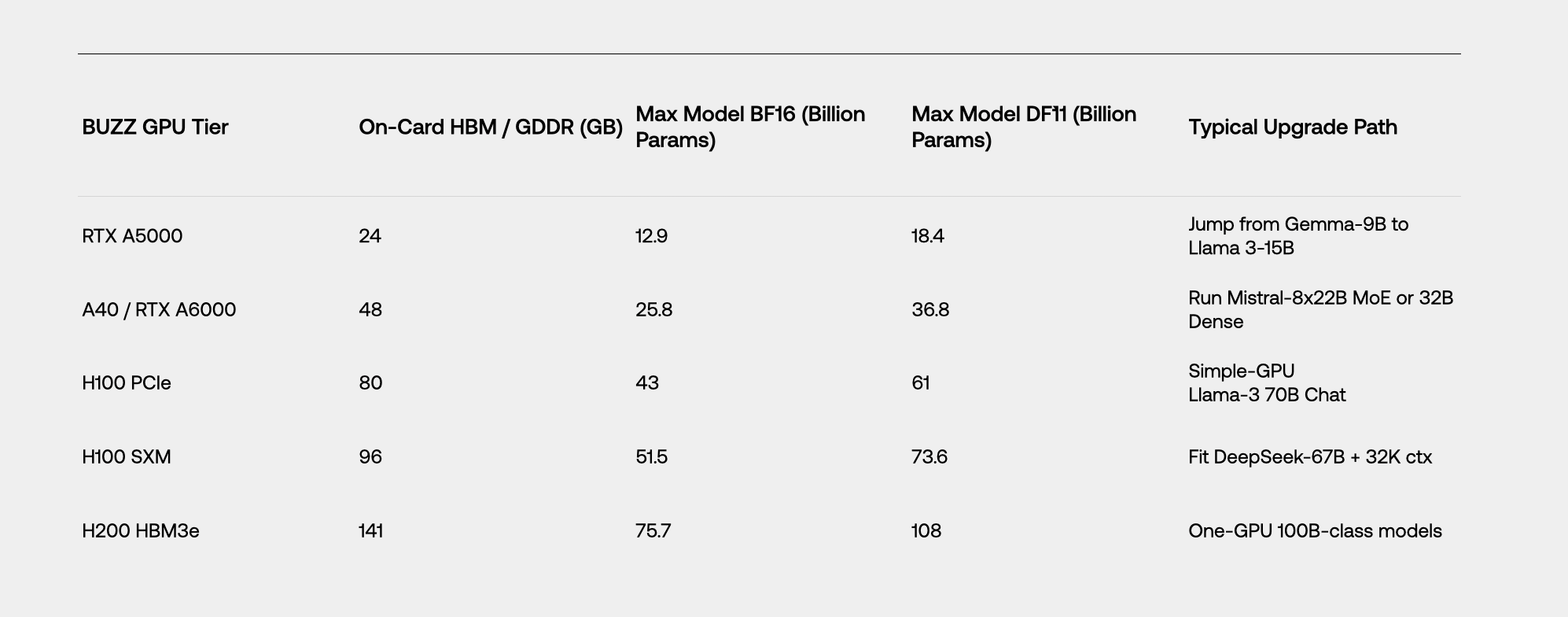
Le KV-cache l’emporte. Comme DF11 compresse également les activations, les entrées KV de chaque jeton sont réduites de 30 %. Sur les charges de travail de contexte long (historique de chat, RAG, documents ERP), cela se traduit par une longueur de contexte de +43 % avant d’expulser les jetons.
Performance en pratique
- Débit : pour des batchs ≥ 32, le décodage DF11 est amorti ; sur une A100 40 Go, l’équipe a constaté une baisse de performance de seulement 2 % par rapport au BF16.
- Cas limites de latence : Batch = 1 voit ~40 % hit - utilisez BF16 lorsque vous êtes déjà en forme et ne vous souciez que du ping à une seule invite.
- Offre des performances jusqu’à 38x supérieures au déport vers le CPU lorsque l’autre option est un débordement vers la RAM.
Comment utiliser DF11 sur BUZZ
- Hugging Face : des checkpoints DF11 prêts à l’emploi pour Llama-3.x, Qwen 2.x, Mistral, etc.
- DIY :
dfloat11.compress.py your_model_dirpermet de produire un modèle DF11 au format.pt, compatible avec vLLM et TensorRT-LLM. - Parcs mixtes : le scheduler de BUZZ permet de packager des shards DF11 sur des GPU hétérogènes ; comme DF11 est bit-exact, les résultats restent déterministes d’un appareil à l’autre.
Impact sur les coûts
Exécution de Llama‑3‑70B‑Instruct sur un seul H100‑80 Go avec DF11 par rapport à deux H100 avec BF16 :

Annualisé, cela représente des économies de plus de 47 000 $par réplique avant les rabais d’alimentation.
Quand ne pas utiliser DF11
- Vous êtes satisfait de la quantification W8A8 avec perte et avez déjà validé la qualité.
- Points de terminaison critiques en termes de latence, par lots, qui s’intègrent déjà dans la VRAM.
- Entraînement ou réglage fin du gradient complet (les bits d’exposant changent).
L’efficacité suscite l’appétit avec le paradoxe de Jevons
En 1865, l’économiste William Stanley Jevons a observé que les gains d’efficacité techniques ont tendance à augmenter la consommation globale d’une ressource, parce que la baisse des coûts débloque de nouveaux cas d’utilisation. BUZZ voit déjà cette dynamique avec les pilotes DF11 :
- Des équipes qui ne pouvaient se permettre que des assistants de 7 milliards de paramètres le trimestre dernier déploient désormais des chatbots de 34 milliards de paramètres — et ont besoin d’une longueur de contexte quatre fois supérieure.
- Les intégrateurs RAG qui ont pressé l’inférence dans un GPU par locataire lancent maintenant des pools de rafale de 20 à 30 instances pour gérer le reclassement complet des documents.
À retenir : DF11 réduit fortement le coût unitaire, mais la demande globale dépassera probablement les gains réalisés. L’extension prochaine des centres de données de BUZZ — combinée à de nouveaux stocks de H100/H200 — garantit que les capacités suivront la hausse induite par la courbe de Jevons.
Conception pour l’échelle : traitez votre migration DF11 comme l’étape 1. L’étape 2 est la politique de mise à l’échelle automatique, les groupes de placement et la vitesse inter-GPU (NVLink vs PCIe) afin que vous puissiez surfer sur la vague de la demande sans goulots d’étranglement.



